
Building an Efficient Retrieval Augmented Generation (RAG) System for Legal Document — Q&A Chatbot - Part 2
Evaluating the RAG System
To ensure that our RAG system performs optimally, we need to evaluate it using a structured framework. RAGAS (Retrieval-Augmented Generation Assessment System) provides the tools and metrics necessary for thorough evaluation.
Introducing RAGAS
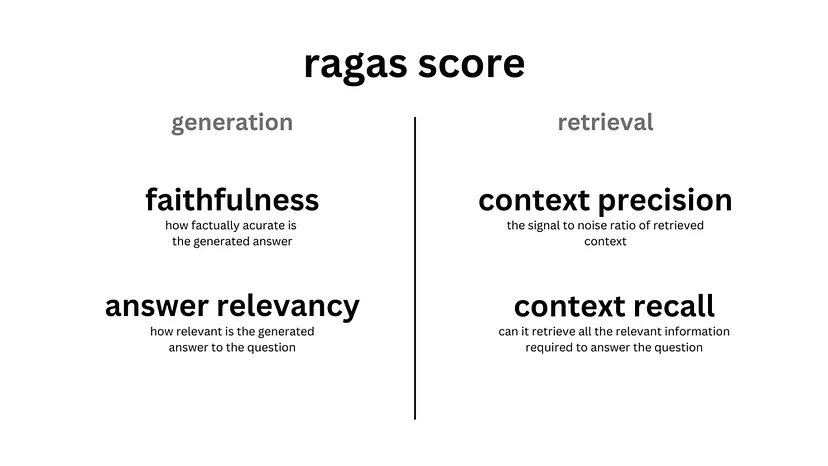
RAGAS is a system designed to assess the performance of Retrieval Augmented Generation (RAG) models. It offers various metrics such as:
-
Faithfulness: Measures the factual accuracy of the generated answer with the context provided. This is done in two steps:
- Given a question and generated answer, RAGAS uses an LLM to extract the statements made by the generated answer.
- Given the list of statements and the context returned, RAGAS uses an LLM to check if the statements are supported by the context. The score is obtained by dividing the number of correct statements by the total number of statements in the generated answer.
-
Answer Relevancy: Measures how relevant and to the point the answer is to the question. RAGAS uses an LLM to find probable questions that the generated answer could respond to and computes the similarity to the actual question asked.
-
Context Relevancy: Measures the signal-to-noise ratio in the retrieved contexts. RAGAS identifies sentences from the retrieved context needed to answer the question and calculates the ratio between the necessary sentences and the total sentences in the context.
-
Context Recall: Measures the retriever’s ability to retrieve all necessary information needed to answer the question. RAGAS checks if each statement from the ground truth answer can be found in the retrieved context and calculates the proportion of statements supported by the retrieved context.
Most of the measurements do not require any labeled data, making it easier for users to run it without worrying about building a human-annotated test dataset first. In order to run RAGAS, all you need is a few questions and, if you're using context recall, a set of question-and-answer pairs.
Install RAGAS
First, ensure RAGAS is installed in your environment:
pip install ragas==0.1.8 # we had thread issues with latest RAGAS
Creating an Evaluation Dataset
We will use a predefined set of legal documents and queries to evaluate the performance of our RAG system. Here is an example evaluation dataset:
{
"questions": [
"What is the termination notice period for the employment contract?",
"What are the confidentiality obligations in the advisory agreement?"
],
"ground_truths": [
"This is a sample contract about employment. The termination notice period is 30 days.",
"This advisory agreement includes confidentiality obligations that require the advisor to keep all company information confidential for a period of two years after the termination of the agreement."
]
}
Define Evaluation Script
Create an evaluation script that uses RAGAS to evaluate different configurations of our RAG system.
First, we load our QA for question and the ground truth:
import yaml
def load_eval_qa():
with open("data/evaluation/raptor.json", "r") as f:
return yaml.safe_load(f)
qa = load_eval_qa()
Then, we can iterate over the questions to get the generated answers:
import requests
url = "http://127.0.0.1:8000/qa/hyde_chunk300_50_test_ragas"
answers = []
contexts = []
for q in qa['questions']:
data = {
"query": q
}
response = requests.post(url, json=data)
print(response.json()['response'])
answers.append(response.json()['response'])
contexts.append(response.json()['context'])
Once that is done, our API returns with the context it uses and its generated answer for the question, so we will build a dataset that we can use to evaluate our RAG:
from datasets import Dataset
# To dict
data = {
"question": qa['questions'],
"answer": answers,
"contexts": contexts,
"ground_truth": qa['ground_truths']
}
# Convert dict to dataset
dataset = Dataset.from_dict(data)
Now, run the evaluation script with different configurations to assess the performance of various chunking and retrieval strategies. Analyze the results to determine which configuration provides the best performance based on the defined metrics:
from ragas import evaluate
from langchain_openai import ChatOpenAI
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
)
result = evaluate(
dataset=dataset,
llm=ChatOpenAI(model="gpt-4-preview", temperature=0), # use gpt-4o to increase context window, but has high cost
metrics=[
context_precision,
context_recall,
faithfulness,
answer_relevancy,
],
)
Now that we run it, what is next?
After running the evaluation script, analyze the results to identify the best-performing configuration. Compare the scores for faithfulness, answer relevancy, context relevancy, and context recall across different configurations to determine which setup yields the most accurate and relevant responses.
Evaluation Configurations
We tested several configurations with different chunking methods, chunk sizes, query translations, and retrieval strategies. The configurations included:
- Rag Fusion with Chunk Size 300, Chunk Overlap 50
- Recursive Chunking with Chunk Size 300, Chunk Overlap 50
- Semantic Chunking
- Character Chunking with Chunk Size 2000, Chunk Overlap 300
- Chunk Size 200, Chunk Overlap 30
- Text Character Splitter Chunk Size 2000, Chunk Overlap 300
- Sentence Splitter Chunk Size 300, Chunk Overlap 50
- Multi Query Retrieval
- Rag Fusion with Chunk Size 200, Chunk Overlap 30
We started with a simple recursive text splitter with chunk size 2000 but got a terrible result in overall efficiency, which was around 61%.
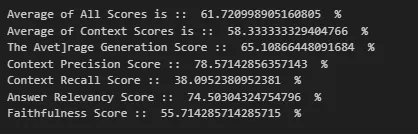
- Context recall was also very low, i.e., 38%, indicating a significant impact on retrieval quality due to poor context matching. Thus, we implemented a query transformation.
Query Transformations
Since the search query to retrieve additional context in a RAG pipeline is also embedded into the vector space, its phrasing can impact the search results. We experimented with various query transformation techniques, including:
- RAG Fusion: Use an LLM to rephrase the query and try again.
- Hypothetical Document Embeddings (HyDE): Use an LLM to generate a hypothetical response to the search query and use both for retrieval.
- Multi Queries: Break down longer queries into multiple shorter queries.
Evaluation Test with Multi Query
With our multi-query test, with chunk size reduced to 300 and overlap 20, we observed:
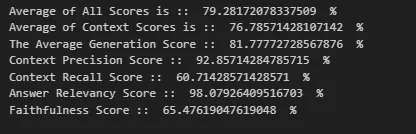
- The average total score increased significantly to 79.28%, ranking as the third-best method so far.
- Context recall nearly doubled to 60.71% from 38%, while answer relevancy improved to 98.07% from 74.5%.
Evaluation Test with Hypothetical Document Embeddings (HyDE)
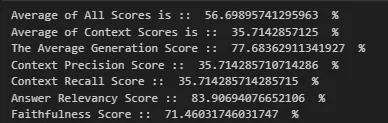
With the HyDE method of query translation, our RAG performed poorly on all benchmarks, yielding similar results to our initial configuration.
Evaluation Test with RAG Fusion — RRF
The RAG Fusion technique uses Reciprocal Rank Fusion (RRF), a data re-ranking technique deployed to combine the results from different queries seamlessly. It aims to organize the search results in a unified ranking, improving the accuracy of relevant information.
- Metrics with RAG Fusion and chunk size 300 and chunk overlap of 50 revealed outstanding scores, achieving 81.09% on all benchmarks and excelling in answer relevancy and context precision.
- However, context recall declined, potentially due to improved generation scores while increased retrieval complexity.
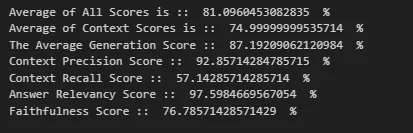
Indexing
Indexing mechanisms play a crucial role in RAG and RAPTOR systems by enabling efficient and accurate retrieval of relevant documents or passages from a large corpus.
RAPTOR - Recursive Abstractive Processing for Tree-Organized Retrieval
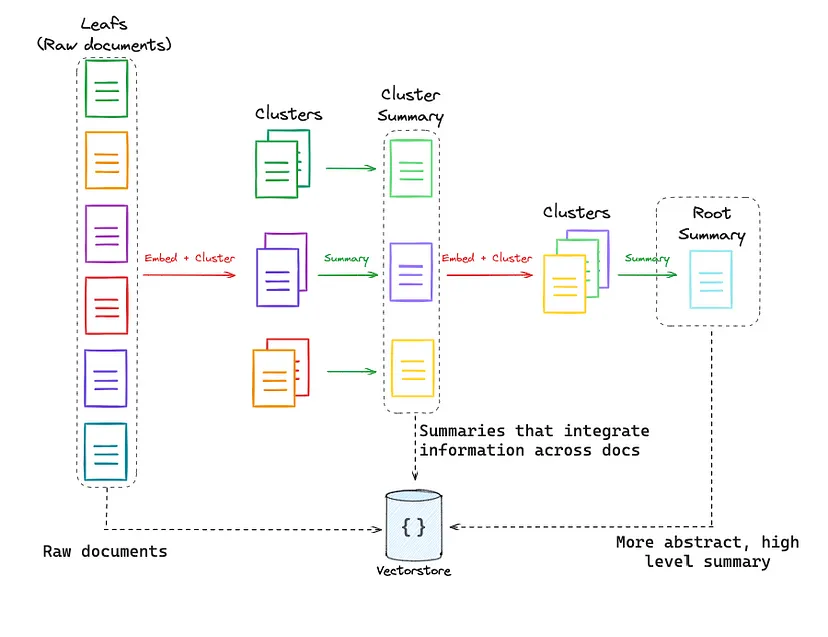
The RAPTOR paper presents an interesting approach for indexing and retrieval of documents:
- Leaf Nodes: Starting documents are embedded and clustered.
- Clusters: Clusters are summarized into higher-level (more abstract) consolidations of information across similar documents.
- Recursive Process: This process is done recursively, resulting in a tree that goes from raw documents (leaf nodes) to more abstract summaries.
In our implementation of RAPTOR, we observed significant improvement in RAG's overall and context recall evaluations.
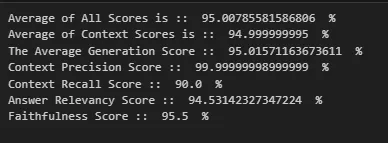
Optimizing with Hybrid Search & Reranking
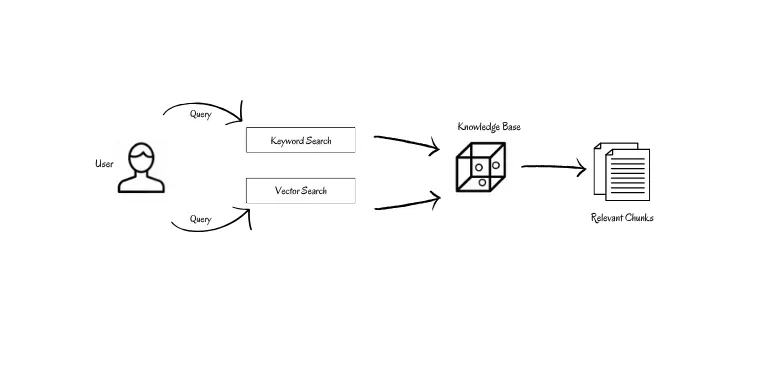
Hybrid search combines dense (Vector) and sparse (Keyword) search methods to unlock new levels of efficiency and accuracy.
In our implementation, we used both third-party applications like Weaviate and Chroma. We added both implementations to our retriever class and configured them in our configuration file.
Running Evals on Hybrid Database
The hybrid search performed well when coupled with RAG Fusion query transformation. The results showed improved context precision, although metrics like context recall were still average compared to other techniques.
Building a Chat Interface with React — Frontend Implementation
The frontend was implemented using React to create a dynamic and responsive chat interface.
Component Structure
We have two main components in our chat interface:
- Conversation List: Displays the list of recent conversations.
- Messages: Displays the chat history for a selected conversation.
We used the useEffect hook to fetch conversation and history data and stored it using the useState hook. The Messages component ensures that both AI and human messages are displayed correctly without distorting the layout.
Conclusion and Limitations
Conclusion
In this post, we embarked on building, evaluating, and optimizing a RAG system tailored for legal documents. Key steps included:
- Introduction to RAG Systems: Overview of RAG systems and their importance in handling complex legal texts.
- Setting Up the Project: Project environment setup, structuring directories, and installing necessary tools.
- Building the RAG System: Backend configuration using FastAPI, PostgreSQL integration, and QA implementation using OpenAI models.
- Evaluating the RAG System: Using RAGAS to define metrics, create an evaluation dataset, and run evaluations with different configurations.
- Experimentation and Optimization: Experimenting with different chunking and retrieval strategies, component swapping, and fine-tuning based on evaluation results.
Limitations
- Scalability: As the document corpus grows, retrieval can become slower and less efficient.
- Handling Ambiguity: The system may struggle with highly nuanced or ambiguous questions.
- Continuous Improvement: Regular updates and user feedback are crucial for maintaining accuracy.
- Legal Expertise: Legal domain knowledge would help refine answers and evaluations.
Despite these limitations, our RAG system provides a strong foundation for handling legal documents and offers significant potential for further enhancements.
Contacts For any questions, feedback, or further assistance, feel free to reach out:
- GitHub: https://github.com/dev-abuke
- LinkedIn: https://www.linkedin.com/in/abubeker-shamil/
Thank you for following along with this post. We hope you found it informative and helpful in building your own RAG system.
Happy RAG!