
Building an Efficient Retrieval Augmented Generation (RAG) System for Legal Document — Q&A Chatbot - Part 1
Introduction
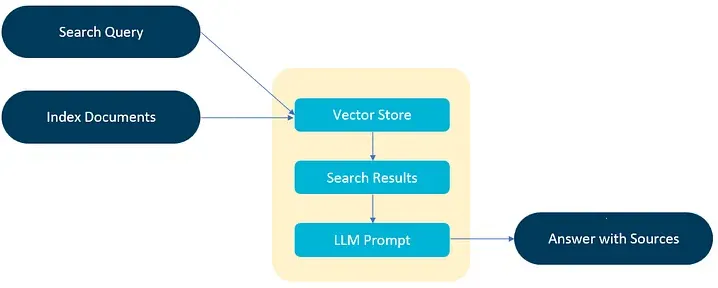
In the world of Natural Language Processing (NLP), Retrieval Augmented Generation (RAG) has emerged as a powerful technique that combines the strengths of information retrieval and text generation to create highly accurate and contextually relevant responses. In this post, we will walk through the process of building a RAG system tailored for answering questions about legal documents. We’ll cover the end-to-end workflow, from setting up the backend with FastAPI and Frontend with React to evaluating different configurations using RAGAS.
Retrieval Augmented Generation (RAG)
RAG combines the strengths of information retrieval and text generation to create systems capable of answering complex queries with contextually relevant and accurate responses. Traditional retrieval systems can quickly fetch relevant documents like Google indexing millions of webpages in a second, but they often fall short in generating coherent and precise answers. Conversely, generative models can create human-like text but may lack the necessary context or domain-specific knowledge. RAG bridges this gap by integrating retrieval mechanisms with generative models, enabling the generation of well-informed and context-aware responses.
RAG systems are particularly beneficial in domains that require precise and context-sensitive information, such as legal document processing. By leveraging RAG, legal professionals or not, can efficiently query large corpora of legal texts, retrieve relevant documents, and generate accurate and concise answers to specific legal questions.
Project Objective
Our primary goal is to build a robust RAG system tailored for handling legal documents. We will address how to set up a FastAPI backend, integrate it with OpenAI models, implement various chunking, query transformation and retrieval strategies, evaluate the system using RAGAS, and experiment with different configurations to optimize performance.
By the end of this post, we will have a comprehensive understanding of:
- Setting up a FastAPI application for RAG.
- Integrating PostgreSQL for database management.
- Utilizing OpenAI models for embedding and text generation.
- Implementing and experimenting with different chunking and retrieval strategies.
- Evaluating the RAG system using RAGAS.
- Optimizing the system for better performance.
Considerations in Building Q&A RAG
Building a Retrieval-Augmented Generation (RAG) Q&A application is easy but making it production-ready and scalable is very difficult. We need to consider different aspects such as:
- Latency
- Cost of retrieval and generation using LLM
- Answer Relevancy (how precise the answer should be)
Getting the RAG pipeline’s performance to a satisfying state is especially difficult because of the different components in a RAG pipeline:
- Retriever component: retrieves additional context from an external database for the LLM to answer the query.
- Generator component: generates an answer based on a prompt augmented with the retrieved information.
Hence the efficiency of the above pipeline is essential for the overall performance of the RAG.
Setting Up the Project
Project Structure
Before diving into the implementation, it’s essential to organize our project in a structured manner. This ensures that our code is maintainable and scalable. Here’s a simple overview of our project structure:
my_rag_project/
│
├── app/
│ ├── __init__.py
│ ├── main.py # Entry point for the FastAPI application.
│ ├── config.py
│ ├── models.py
│ ├── schemas.py
│ ├── database.py
│ ├── factory.py # Factory methods for creating components.
│ ├── routers/
│ │ ├── __init__.py
│ │ ├── qa.py
│ │ └── history.py
│ └── services/ # Business logic and service layer
│ ├── __init__.py
│ ├── qa_service.py
│ └── history_service.py
├── data/
│ ├── raw/
│ │ └── law_docx/
│ └── evaluation_data.json
├── requirements.txt
└── config.yaml # houses our configuration for tweaking hyperparameter
Environment Setup To start, we need to set up our development environment with the necessary tools and libraries. Follow these steps to get everything installed and configured.
Install Python and Virtual Environment
Ensure you have Python 3.10 or higher installed. You can download it from the official Python website. Once installed, create a virtual environment for the project:
python -m venv myenv
source myenv/bin/activate # On Windows use `myenv\Scripts\activate`
Install Required Libraries
Create a requirements.txt file with the following content:
fastapi
uvicorn
sqlalchemy
asyncpg
databases
pydantic
pyyaml
openai
langchain
ragas
# Refer to my GitHub repo for more dependencies
Install the dependencies using pip:
pip install -r requirements.txt
Create Configuration File
Create a config.yaml file to manage our component settings, which is essential to tweak our hyperparameters to find out our efficient params.
Below is my configuration:
model: "gpt-4o" # gpt-4o, gpt-3.5-turbo, gpt-4-turbo
embedding: "openai"
retriever: "dense" # dense, sparse, hybrid
text_splitter: "semantic" # sentence, character, semantic, recursive
prompt: "history_aware" # history_aware, contextualize_q, qa_assistant
chunk_size: 300 # chunk_size
chunk_overlap: 50 # chunk_overlap
query_translation: "hyde" # multi_query, rag_fusion, decomposition, hyde
As you can see above, we have different params as we will see later in this post how we will leverage them. This configuration file will allow us to easily swap out models, embeddings, and retrievers as needed.
Building the RAG Backend System
Configuring the FastAPI Backend
FastAPI is a modern, fast web framework for building APIs with Python based on standard Python type hints and pydantic. It is easy to set up and provides great performance.
Install FastAPI and Uvicorn
If you haven’t already installed FastAPI and Uvicorn, you can do so by running:
pip install fastapi uvicorn
Create the Initial FastAPI Application
Create a new file named main.py inside the app directory. This file will serve as the entry point for our FastAPI application:
import os
from langchain_community.document_loaders import Docx2txtLoader
from fastapi import FastAPI
from .database import engine, SessionLocal
from .models import Base
from .routers import qa, history
from .retriever import get_retriever_instance
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
logger.info("Logger CWD:: " + os.getcwd())
# Create the database tables
Base.metadata.create_all(bind=engine)
app = FastAPI()
# Include routers
app.include_router(qa.router)
app.include_router(history.router)
def get_document_from_docx(documents: list, file_path):
# Load and parse HTML file found in the specified folder and subfolders
docx_files = [os.path.join(file_path, f) for f in os.listdir(file_path) if f.endswith('.docx')]
# Load and parse HTML files
for file in docx_files:
loader = Docx2txtLoader(file)
documents.extend(loader.load())
return documents
# Initialize the retriever with documents
documents = get_document_from_docx([], "data/raw/docx")
len_documents = len(documents)
logger.info(f"The Logger INFO :: {len_documents}")
retriever = get_retriever_instance(documents).store_documents(documents)
This sets up a basic FastAPI application with a root endpoint that sets up the initial legal docs into a vector database for initial processing. We also include routers for the QA and history endpoints, which we will define later.
Database Integration with PostgreSQL
We will use SQLAlchemy for database ORM (Object Relational Mapping) for asynchronous database interactions.
Configure Database Connection
Create a file named database.py inside the app directory. This file will handle the database connection setup and session management:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
import os
SQLALCHEMY_DATABASE_URL = os.getenv("DATABASE_URL")
engine = create_engine(SQLALCHEMY_DATABASE_URL)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
# Dependency to get DB session
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
We have used Render AWS redundant Postgres database for this, but any database will work fine.
Define Database Models
Next, we define our database models in a file named models.py:
# app/models.py
from sqlalchemy import Column, Integer, String, Text, DateTime
from .database import Base
from datetime import datetime
class ChatHistory(Base):
__tablename__ = 'chat_history'
id = Column(Integer, primary_key=True, index=True)
session_id = Column(String, index=True)
message = Column(Text)
timestamp = Column(DateTime, default=datetime.utcnow)
Create Pydantic Schemas
Create a file named schemas.py to define Pydantic models for request and response validation:
# app/schemas.py
from pydantic import BaseModel
from datetime import datetime
from typing import List
class QueryRequest(BaseModel):
query: str
class QueryResponse(BaseModel):
response: str
class MessageHistory(BaseModel):
session_id: str
message: str
class MessageHistoryResponse(BaseModel):
id: int
session_id: str
message: str
timestamp: datetime
class Config:
orm_mode = True
Create QA Router
One of the essential routes is the QA route, as this will be the first communication channel between the user and our RAG application.
Create a file named qa.py inside the routers directory. This file will handle the question-answering endpoints:
# app/routers/qa.py
from fastapi import APIRouter, Depends, HTTPException
from sqlalchemy.orm import Session
from ..schemas import QueryRequest, QueryResponse
from ..database import get_db
from ..services.qa_service import get_answer
router = APIRouter()
@router.post("/qa", response_model=QueryResponse)
async def qa_endpoint(query: QueryRequest, db: Session = Depends(get_db)):
response = await get_answer(query, db)
return QueryResponse(response=response)
Factory Methods for Component Swapping
We have seen the overview of our implementation FastAPI, routers, and databases. Now we shall see an essential component of our RAG application, which is a factory method for creating and managing different components (models, embeddings, retrievers) to allow easy swapping and configuration. We’ll also ensure our system is flexible and can be easily adapted for various scenarios.
Building the RAG System
To create a flexible system that allows easy swapping of models, embeddings, and retrievers, we need to implement factory methods. This will enable us to experiment with different configurations without modifying the core logic of our application.
Abstracting Component Interfaces
We’ll start by defining abstract interfaces or base classes for our components. This ensures that all implementations adhere to a common structure.
Create the Factory File
Create a file named factory.py inside the app directory. This file will contain our factory methods:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from .chunking import TextSplitter
from .config import load_config
# makes the .env file in the same directory
import os
from dotenv import load_dotenv
load_dotenv()
def get_model():
config = load_config()
if config["model"] == "gpt-3.5-turbo":
return ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
elif config["model"] == "gpt-4o":
return ChatOpenAI(model="gpt-4o", temperature=0)
# Add more models as needed
def get_embedding():
config = load_config()
if config["embedding"] == "openai":
return OpenAIEmbeddings()
elif config["embedding"] == "huggingface":
return "HuggingFaceEmbeddings"
# Add more embeddings as needed
def get_retriever():
config = load_config()
if config["retriever"] == "dense":
return "DenseRetriever(documents)"
elif config["retriever"] == "sparse":
return "SparseRetriever(documents)"
# Add more retrievers as needed
def get_prompt():
from .generator import create_context_prompt, get_qa_assistant_prompt, create_history_aware_prompt
config = load_config()
if config["prompt"] == "history_aware":
return create_history_aware_prompt()
elif config["prompt"] == "contextualize_q":
return create_context_prompt()
elif config["prompt"] == "qa_assistant":
return get_qa_assistant_prompt()
# Add more prompts as needed
def get_text_splitter() -> TextSplitter:
config = load_config()
chunk_size = config["chunk_size"]
chunk_overlap = config["chunk_overlap"]
if config["text_splitter"] == "character":
return TextSplitter("Character", chunk_size, chunk_overlap)
elif config["text_splitter"] == "sentence":
return TextSplitter("Sentence", chunk_size, chunk_overlap)
elif config["text_splitter"] == "recursive":
return TextSplitter("Recursive", chunk_size, chunk_overlap)
elif config["text_splitter"] == "semantic":
return TextSplitter("Semantic", chunk_size, chunk_overlap)
# Add more text splitters as needed
def get_query_translation():
config = load_config()
from .generator import get_answer_using_multi_query, get_answer_using_rag_fusion, get_answer_using_decomposition, get_answer_using_hyde
if config["query_translation"] == "multi_query":
return get_answer_using_multi_query
elif config["query_translation"] == "rag_fusion":
return get_answer_using_rag_fusion
elif config["query_translation"] == "decomposition":
return get_answer_using_decomposition
elif config["query_translation"] == "hyde":
return get_answer_using_hyde
# Add more query translation as needed
With the factory methods and previous configuration management in place, we have a flexible system that allows us to easily swap out different components and configurations. This sets the stage for running evaluations and experimenting with various setups.
Understanding and Visualizing Token Counts in Document Processing
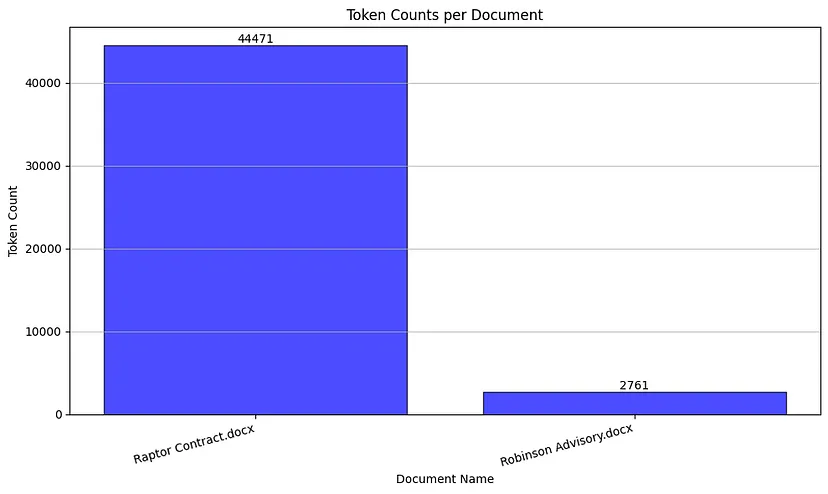
When working with large documents in natural language processing (NLP) tasks, one critical aspect to consider is the token count of each document. Tokens are the individual pieces of the text that models like GPT-3.5 process, and understanding their distribution across documents is essential for efficient and effective model performance.
Why Visualize Token Counts?
Visualizing token counts helps us in several ways:
- Context Window Management: GPT-3.5 has a maximum context window of 16k tokens. If a document exceeds this limit, it must be split or truncated, which can lead to loss of critical information or increased complexity in handling multiple parts. By visualizing token counts, we can easily identify documents that exceed this limit.
- Performance Optimization: When documents of vastly different lengths are processed together, shorter documents may not fully utilize the model’s capacity, while longer documents may need to be split, complicating the processing pipeline. Visualizing helps us balance the document lengths for optimal performance.
- Resource Allocation: Longer documents require more costly resources for processing. Knowing the token distribution allows us to allocate resources efficiently, ensuring that longer documents are given adequate processing power without over-allocating resources to shorter documents.
Code — Visualizing Token Counts
We used the tiktoken library to calculate the token counts and matplotlib to create a bar chart that displays these counts. Below is the Python code to achieve this visualization:
import matplotlib.pyplot as plt
import tiktoken
import os
# Load and parse docx files found in the specified folder and subfolders
def get_document_from_docx(documents: list, file_path):
docx_files = [os.path.join(file_path, f) for f in os.listdir(file_path) if f.endswith('.docx')]
for file in docx_files:
loader = Docx2txtLoader(file)
documents.extend(loader.load())
return documents
# Initialize the retriever with documents
docs = get_document_from_docx([], "data/raw/docx")
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
# Document texts and names
docs_texts = [d.page_content for d in docs]
doc_names = [os.path.basename(d.metadata['source']) for d in docs] # Assuming metadata contains 'source'
# Calculate the number of tokens for each document
counts = [num_tokens_from_string(d, "cl100k_base") for d in docs_texts]
# Plotting the bar plot of token counts
plt.figure(figsize=(10, 6))
bars = plt.bar(doc_names, counts, color="blue", edgecolor="black", alpha=0.7)
# Annotate bars with the token count
for bar, count in zip(bars, counts):
plt.text(bar.get_x() + bar.get_width() / 2, bar.get_height(), str(count), ha='center', va='bottom')
plt.xticks(rotation=15, ha='right')
plt.title("Token Counts per Document")
plt.xlabel("Document Name")
plt.ylabel("Token Count")
plt.grid(axis="y", alpha=0.75)
# Display the bar plot
plt.tight_layout()
plt.show()
Insights from Visualization
The resulting bar chart clearly shows the token count for each document. In this specific case, we observe that Raptor has an extremely high token count of 44k, while Robinson has a much lower count of 2.7k tokens. This disparity highlights a few critical points:
- The Raptor document cannot be processed in a single context window of GPT-3.5. We need to split this document into smaller chunks, ensuring each chunk fits within the 16,000 token limit. This splitting must be done carefully to preserve the context and meaning.
- Including both token documents in the same batch could lead to inefficient processing. The smaller document might get processed quickly, while the larger document requires more time and resources, potentially affecting latency and cost.
With all that in place, In Part 2 we will move on to the actual fun part we were building up to — RAG Evaluation using and opensource tool called RAGAS